欢迎光临三亚视窗!
今天是 2024年12月25日 星期三
关注社会热点
一起实现我们的中国梦
来源:DeepTech深科技
自大模型问世以来,该领域有越来越多的研究者,开始关注其在战略决策中的应用潜力。
美国罗格斯大学华文越博士(现为美国加利福尼亚大学圣巴巴拉分校博士后)及其所在课题组认为,如果能够掌握大模型行为的理性程度,包括噪音、数值扰动、智能体之间言语交互的鲁棒性等等,就能对大模型模拟的结果进行量化评估,从而了解模拟结果的可靠性,及其背后的动机和决策能力。
 图丨华文越(来源:华文越)
图丨华文越(来源:华文越)基于此,该团队从博弈论出发,研究了大模型在战略决策情境中的理性。
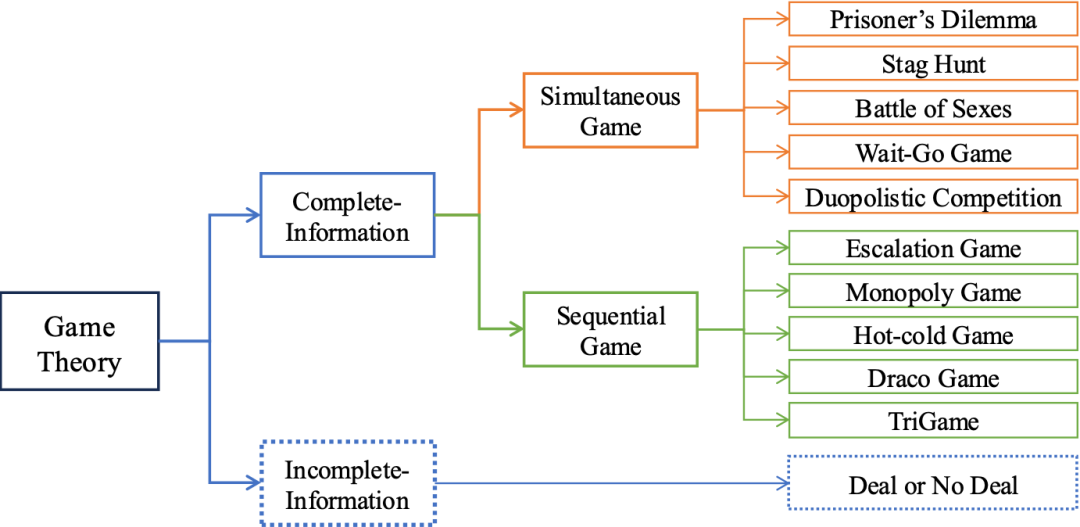 图丨本文研究的博弈论景观(来源:arXiv)
图丨本文研究的博弈论景观(来源:arXiv)在一系列信息完全和信息不完全的博弈论场景中,研究人员对大模型进行评估,结果发现其经常偏离理性,特别是随着游戏复杂性的增加,如面对更大的收益矩阵或更深层次的顺序树时,大模型的理性表现会显著下降。
具体来说:
在信息完全的场景下,研究人员采用相对成熟的博弈论来构建工作流程。
而在信息不完全的场景下,他们首先假设对方是理性人,或双方都希望能够达成交易,并且尽可能最大化各自的回报。
然后,根据当前对对方估值的猜测提出资源分配提案,并根据对方对提案的态度进行贝叶斯更新,以此来调整自己对于对方估值的评估。
为了增强大模型的理性能力,该课题组设计了多个博弈论工作流程,用以指导大模型的推理和决策过程。
这些工作流程旨在增强模型计算纳什均衡(也就是理性决策),以及在不确定性和不完全信息条件下做出理性选择的能力。
实验结果显示:
在信息完全的场景下,工作流程的实施显著提升了大模型在博弈论环境中的性能,即更加擅长计算纳什均衡,并选择最优策略。
然而,问题仍然存在。比如,由于数值计算错误,基于大模型的智能体即使按照工作流程进行思考,也无法准确地推导纳什均衡。
因此,尽管工作流程改进了理性决策,但它并未完全消除所有因计算导致的能力问题和能力限制。
另外,即便是在使用工作流程的情况下,谈判仍然可能使大模型偏离通过工作流程推理得出的纳什均衡策略。
基于大模型的智能体依然会受到谈判对话的影响,偶尔会选择非理性策略。
在信息不完全的场景下,所有使用工作流程的大模型都能实现非常接近最优分配的结果,并且它们的谈判过程能够 100% 成功完成。
当两个基于大模型的代理都使用工作流程时,所有模型都能够稳定地实现接近最佳可能结果的分配。
与此同时,通过工作流程增强的大模型,在估计对手的估值方面,表现出显著的精确性。
它们能够有效地将可能的估值集,从 1000 种可能性缩减到仅有 2 或 3 个可能性,并且所有这些选项都 100% 包含真实估值。
这种强劲的表现表明,基于工作流程的谈判是非常有效的。
近日,相关论文以《博弈论大语言模型:谈判游戏的智能体工作流程》(Game-theoretic LLM: Agent Workflow for Negotiation Games)为题在预印本平台 arXiv 上发布 [1]。
华文越是第一作者,罗格斯大学王欣曈助理教授和张永锋助理教授担任共同通讯作者。
 图丨相关论文(来源:arXiv)
图丨相关论文(来源:arXiv)显然,如果大模型的理性能力能够得到提升,其将在战略决策情境下获得更为广泛的应用。
对此,华文越表示:“我们认为,未来基于大模型的智能代理,不仅可以成为人类的任务助理,还可以作为谈判代表或协助人类进行谈判,做出理性决策并促进社会福利。
这意味着,它们不仅能够巧妙地代表人类在谈判中获取自身利益,还能推动实现帕累托最优,从而使整个社会受益。”
其中,需要说明的是,帕累托最优是博弈论和经济学中的一个概念,指的是一种资源分配状态,能确保资源的分配是公平的。
另外,在该研究的基础上,该团队也想结合心智理论,展开动态的基于博弈论的算法研究。
他们希望大模型可以推理出对方的思维模式、意图和愿望,来计算理性最优解。
参考资料:
1.Hua W, Liu O, Li L, et al. Game-theoretic LLM: Agent Workflow for Negotiation Games.arXiv:2411.05990, 2024.https://doi.org/10.48550/arXiv.2411.05990
运营/排版:何晨龙
 博弈论
博弈论 

 新浪科技公众号
新浪科技公众号 “掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)
 相关新闻
相关新闻